During the Vision 2024 event, Intel announced several news, including details about its new Gaudi 3 AI processors, which it claims offer up to 1.7 times faster learning performance, 50% more accurate solutions, and 40% higher efficiency than NVIDIA H100 processors, but for significantly less money.

NVIDIA's dominance in AI infrastructure and software is undeniable. However, Intel, like AMD, is looking to become an alternative to NVIDIA as the industry continues to struggle with a crippling shortage of AI GPUs.
To that end, Intel has also outlined its full range of AI support programs, which span hardware and software, as it seeks to gain traction in the booming AI market currently dominated by NVIDIA and AMD.
Intel's efforts are focused on developing its partner ecosystem to create ready-made Gaudi 3 solutions, and the company is also working on creating an open enterprise software stack that will serve as an alternative to NVIDIA's proprietary CUDA system.

Intel provided detailed information about the Gaudi 3 architecture along with a variety of compelling benchmarks against the existing NVIDIA H100 GPU.

Intel's Gaudi 3 is the third generation of the Gaudi accelerator, which is the result of Intel's acquisition of Habana Labs for USD 2 billion in 2019. In Q3 2024, Gaudi accelerators will go into production and become generally available for OEM systems.
Intel will also make Gaudi 3 systems available in its cloud for developers, thereby providing accessibility for potential customers to test chips.

The Gaudi is available in two form factors, with the HL-325L OAM (OCP accelerator module) being a common mezzanine form factor in GPU-based high-performance systems. This accelerator has 128 GB of HBM2e memory, which provides 3.7 TB/s of bandwidth. It also has twenty-four 200 Gbps Ethernet RDMA network cards. The HL-325L OAM module has a TDP of 900W and is rated for 1835 TFLOPS of FP8 performance.
Intel claims that Gaudi 3 delivers twice the FP8 performance and four times the BF16 performance of the previous generation, as well as double the network bandwidth and 1.5 times the memory bandwidth. The OAM modules are inserted into a universal panel that holds eight OAMs.
Intel has already shipped OAMs and baseboards to its partners, preparing them for general availability later this year. Scaling up to eight OAMs on the HLB-325 base board delivers performance up to 14.6 PFLOPS FP8, while all other metrics such as memory and bandwidth scale linearly.
Intel also has a dual-slot Gaudi 3 PCIe card with a TDP of 600W. This card also has 128GB of HBM2e and twenty-four 200Gbps Ethernet NICs - Intel says dual 400Gbps NICs are used for scalability. Intel says that the PCIe card has the same peak performance of 1835 TFLOPS FP8 as the OAM. In addition, the company adds that this card can also scale to create larger clusters, but did not provide details.
Dell, HPE, Lenovo, and Supermicro are already developing off-the-shelf solutions based on Gaudi 3. Air-cooled Gaudi models have already been sampled, and liquid-cooled models will be sampled in the second quarter. They will become generally available in the third and fourth quarters of 2024, respectively. The PCIe card will also be available in the fourth quarter.

Intel has shared performance predictions for Gaudi 3. As you'll see in the last image in the album above, Intel provides a QR code for information on its benchmarks. Intel compared publicly available benchmarks for H100 systems, but did not compare to NVIDIA's upcoming Blackwell B200 due to a lack of real-world benchmark data.
The company also didn't provide a comparison with AMD's upcoming Instinct MI300 GPUs, but that's not possible because AMD continues to avoid publishing publicly available performance data from its industry-accepted MLPerf benchmarks.


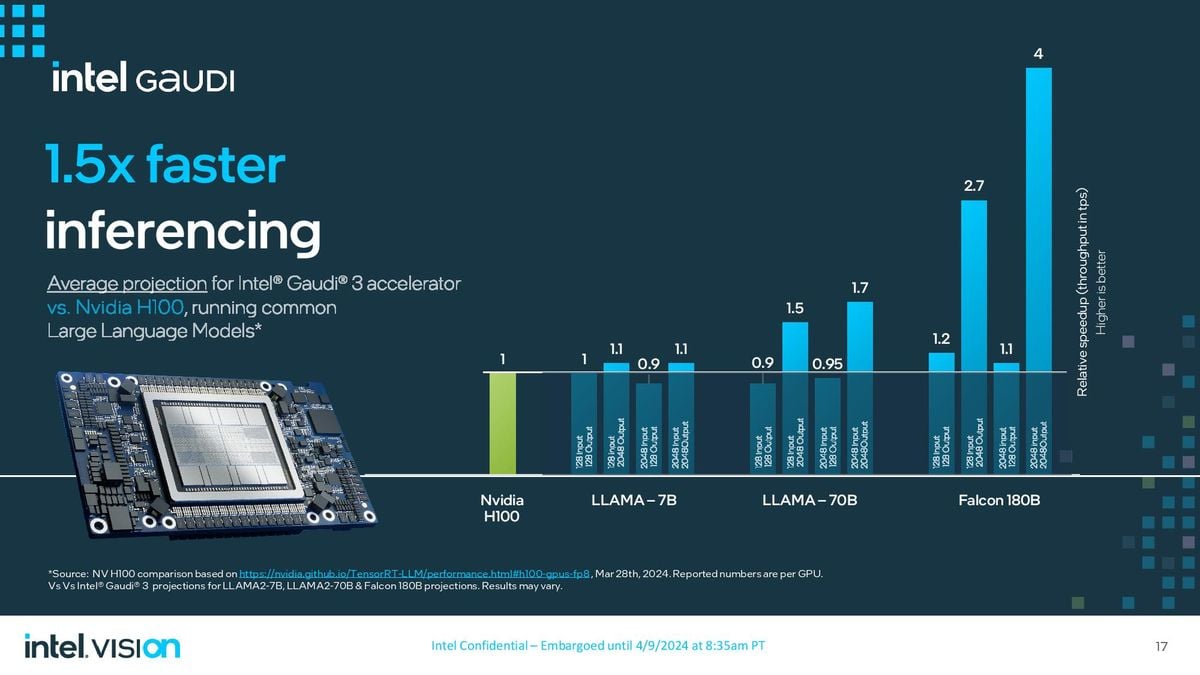
Intel has provided many comparisons for both training and logic workloads compared to the H100 with similar cluster sizes, but the key takeaway is that Intel claims Gaudi is 1.5x to 1.7x faster in training. The comparison includes the LLAMA2-7B (7 billion parameters) and LLAMA2-13B models with 8 and 16 Gaudi respectively, as well as the GPT 3-175B model tested on 8192 Gaudi accelerators, all using FP8.
Interestingly, Intel was not compared to NVIDIA's H200, which has 76% more memory capacity and 43% more memory bandwidth than the H100.


Intel did use the H200 to draw conclusions, but compared performance with a single card as opposed to comparing performance at the cluster level. Here we see a mixed result: five LLAMA2-7B/70B workloads are 10-20% lower than the H100 GPUs, while two match and one slightly exceeds the H200.
Intel claims that Gaudi's performance scales better with larger output sequences, with Gaudi delivering 3.8 times the performance using the Falcon 180 billion parameter model with 2048 lengths of output.
Intel also claims a 2.6x power consumption advantage for inference workloads, which is critical given the constraining power limitations in data centers, but it did not provide similar benchmarks for training workloads.
For these workloads, Intel tested a single H100 in a public instance and logged the H100's power consumption (as reported by the H100), but did not provide examples of inference with a single node or larger clusters. With larger output sequences, Intel again claims better performance and therefore efficiency.