Під час заходу Vision 2024 Intel оголосила кілька новин, зокрема детально розповіла про свої нові процесори Gaudi 3 AI, які, як стверджує, пропонують до 1,7 разу більшу продуктивність навчання, на 50% точніше розв'язання та на 40% вищу ефективність, ніж процесори NVIDIA H100, але за значно менші гроші.

Домінування NVIDIA в інфраструктурі штучного інтелекту та програмному забезпеченні є безперечним. Проте Intel, як і AMD, прагне стати альтернативою NVIDIA, оскільки галузь продовжує боротися з нищівною нестачею графічних процесорів зі штучним інтелектом.
Із цією метою Intel також окреслила повний спектр своїх програм підтримки штучного інтелекту, які охоплюють апаратне та програмне забезпечення, оскільки вона прагне отримати популярність на бурхливому ринку штучного інтелекту, на якому зараз домінують NVIDIA та AMD.
Зусилля Intel зосереджені на розвитку своєї партнерської екосистеми для формування готових рішень Gaudi 3, також компанія працює над створенням відкритого стека корпоративного програмного забезпечення, яке служитиме альтернативою фірмовій системі NVIDIA CUDA.

Intel надала детальну інформацію про архітектуру Gaudi 3 разом із безліччю переконливих тестів порівняно з наявним графічним процесором NVIDIA H100.

Gaudi 3 від Intel є третім поколінням прискорювача Gaudi, який став результатом придбання Intel Habana Labs за 2 мільярди доларів США у 2019 році. У 3 кварталі 2024 року прискорювачі Gaudi надійдуть у виробництво та стануть загальнодоступними для OEM-систем.
Intel також зробить системи Gaudi 3 доступними у своїй хмарі для розробників, забезпечуючи тим самим доступність для потенційних клієнтів для тестування чипів.

Gaudi доступний у двох формфакторах, причому OAM (модуль прискорювача OCP) HL-325L є поширеним мезонінним формфактором у високопродуктивних системах на базі GPU. Цей прискорювач має 128 ГБ HBM2e пам'яті, що забезпечує 3,7 ТБ/с пропускної здатності. Він також має двадцять чотири 200 Гбіт/с Ethernet RDMA мережевих карт. Модуль OAM HL-325L має TDP 900 Вт і розрахований на 1835 TFLOPS продуктивності FP8.
Intel стверджує, що Gaudi 3 забезпечує вдвічі вищу продуктивність FP8 і вчетверо вищу продуктивність BF16, ніж попереднє покоління, а також подвоєну пропускну здатність мережі та 1,5-кратну пропускну здатність пам’яті. Модулі OAM вставляються в універсальну панель, на якій розміщено вісім OAM.
Intel вже поставила OAM і базові плати своїм партнерам, готуючи їх до загальної доступності пізніше цього року. Масштабування до восьми OAM на базовій платі HLB-325 забезпечує продуктивність до 14,6 PFLOPS FP8, тоді як усі інші показники, такі як обсяг пам’яті та пропускна здатність, масштабуються лінійно.
Intel також має двослотову карту Gaudi 3 PCIe з TDP 600 Вт. Ця карта також має 128 ГБ HBM2e і двадцять чотири мережеві карти Ethernet 200 Гбіт/с – Intel каже, що подвійні мережеві карти 400 Гбіт/с використовуються для масштабування. Intel заявляє, що карта PCIe має таку саму пікову продуктивність 1835 TFLOPS FP8, що й OAM. Крім того, компанія додає, що ця карта також може масштабуватися для створення більших кластерів, але не надала подробиць.
Dell, HPE, Lenovo та Supermicro вже розробляють готові рішення на основі Gaudi 3. Зразки моделей Gaudi з повітряним охолодженням вже були відібрані, а вибірка моделей з рідинним охолодженням відбудеться у другому кварталі. Вони стануть загальнодоступними у третьому та четвертому кварталах 2024 року відповідно. Карта PCIe також буде доступна в четвертому кварталі.

Intel поділилася прогнозами продуктивності для Gaudi 3. Як ви побачите на останньому зображенні в альбомі вище, Intel надає QR-код для інформації про свої контрольні показники тестування. Intel порівняла загальнодоступні тести для систем H100, але не порівняла з майбутнім Blackwell B200 від NVIDIA через відсутність реальних порівняльних даних.
Компанія також не надала порівняння з перспективними графічними процесорами Instinct MI300 від AMD, але це неможливо, оскільки AMD продовжує уникати публікації загальнодоступних даних про продуктивність у прийнятих галуззю тестах MLPerf.


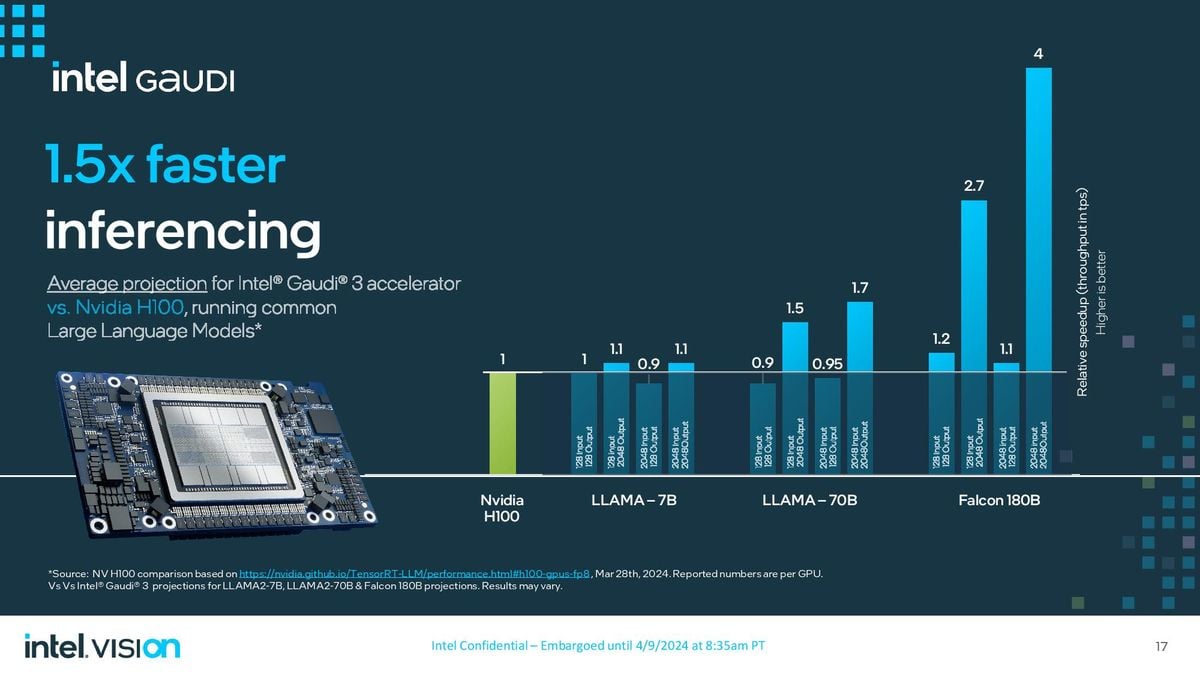
Intel надала багато порівнянь як для навчання, так і для логічного навантаження порівняно з H100 з подібними розмірами кластерів, але ключовим висновком є те, що Intel стверджує, що Gaudi в 1,5 раза до 1,7 раза швидше в навчанні. Порівняння містить моделі LLAMA2-7B (7 мільярдів параметрів) і LLAMA2-13B з 8 і 16 Gaudi відповідно, а також модель GPT 3-175B, протестовану на 8192 прискорювачах Gaudi, усі з використанням FP8.
Цікаво, що тут Intel не порівнювався з H200 від NVIDIA, який має на 76% більшу місткість пам’яті та на 43% більшу пропускну здатність пам’яті, ніж H100.


Intel справді використала H200 для отримання висновків, але порівняла продуктивність з однією карткою на відміну від порівняння продуктивності на рівні кластерів. Тут ми бачимо змішаний результат: п’ять робочих навантажень LLAMA2-7B/70B на 10–20% нижчі за графічні процесори H100, тоді як два збігаються, а один трохи перевищує H200.
Intel стверджує, що продуктивність Gaudi краще масштабується з більшими вихідними послідовностями, при цьому Gaudi забезпечує у 3,8 разу більшу продуктивність за допомогою моделі параметрів Falcon 180 мільярдів із виводом 2048 довжин.
Intel також заявляє про 2,6-кратну перевагу в енергоспоживанні для робочих навантажень із висновками, що є критичним фактором, враховуючи обмежувальні обмеження потужності в центрах обробки даних, але вона не надала подібних контрольних показників для навчальних навантажень.
Для цих робочих навантажень Intel протестувала один H100 у відкритому екземплярі та зареєструвала енергоспоживання H100 (як повідомляє H100), але не надала прикладів висновку з одним вузлом або більшими кластерами. З більшими вихідними послідовностями Intel знову заявляє про кращу продуктивність і, отже, ефективність.