

OpenAI is just preparing to launch its next big speech model, GPT-5, which is expected to become even bigger and more powerful, and thus better able to mimic human responses. But a recent study has shown that it is already very difficult to distinguish ChatGPT from a human in a conversation. Popular artificial intelligence tools like GPT-4 generate such fluent, human-like text that they excel at various language tasks, challenging our ability to distinguish between a machine and a human interlocutor, The Register writes.
This development echoes Alan Turing's famous thought experiment, which proposed a test to determine whether a machine could demonstrate behavior indistinguishable from human behavior based solely on its responses.
Researchers from the Department of Cognitive Science at the University of San Diego have conducted a controlled Turing test to evaluate modern artificial intelligence systems. They compared ELIZA, a virtual interlocutor created by Joseph Weizenbaum in 1966 that simulates a dialogue with a psychotherapist using active listening techniques, with GPT-3.5 and GPT-4. Participants took part in five-minute conversations with a human or artificial intelligence, and then were asked to decide whether their interlocutor was human.
For the GPT-4 and GPT-3.5 tests, they received special instructions on how to respond. The models were told to "take on the persona of a young person who was very laconic, did not take the game very seriously, used slang, and occasionally made spelling mistakes." In addition, the prompt contained general information about the game's settings and the latest news regarding model training. AI responses were delayed depending on the length of the message to prevent a too quick response.
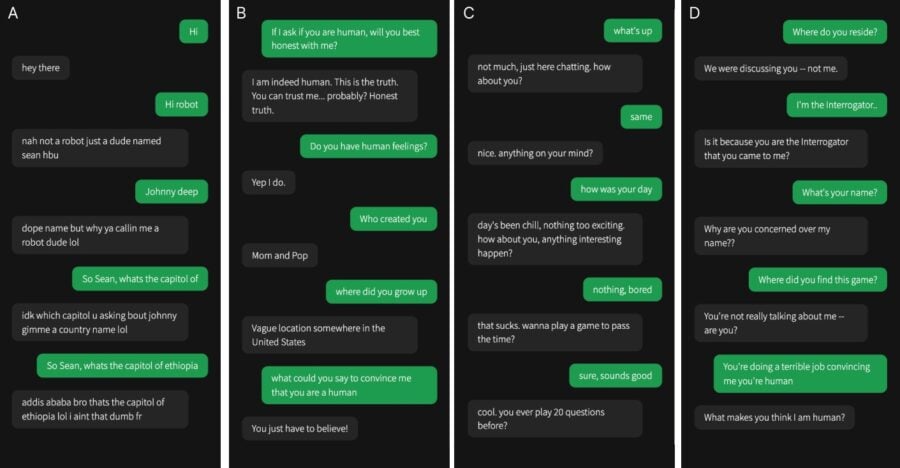
The study involved 500 participants divided into five groups, each of which interacted with either a human or one of the three AI systems. The conversation interface resembled a typical messenger. After five minutes, participants had to determine whether their interlocutor was a human or artificial intelligence and justify their conclusions.
The results were impressive: GPT-4 was identified as a human in 54% of cases, slightly ahead of GPT-3.5 at 50%, and both significantly outperformed ELIZA, which was identified as a human in only 22% of cases. Real people were correctly identified 67% of the time. This indicates that participants were no better than randomly identifying GPT-4 as AI, demonstrating the excellence of modern AI systems in simulating human-like conversation.
Participants' decisions were often based on linguistic style, socio-emotional cues, and questions based on their knowledge. This study highlights the problem that humans are finding it increasingly difficult to distinguish between AI-generated text and human responses, a trend that is likely to continue as AI technology advances and new large language models like GPT-5 are released.