

Компанія OpenAI тільки готує до запуску свою наступну велику мовну модель GPT-5, яка має стати ще більшою та потужнішою, і відповідно краще імітувати відповіді людини. Але нещодавнє дослідження показало, що відрізнити ChatGPT від людини в розмові вже дуже складно. Популярні інструменти штучного інтелекту, такі як GPT-4, генерують настільки вільний, схожий на людський текст, що чудово справляються з різними мовними завданнями, кидаючи виклик нашій здатності відрізнити машину від людського співрозмовника, пише The Register.
Ця розробка перегукується з відомим уявним експериментом Алана Тюрінга, який запропонував тест, щоб визначити, чи може машина демонструвати поведінку, яку неможливо відрізнити від людської, ґрунтуючись виключно на її відповідях.
Для тесту GPT-4 і GPT-3.5 отримали спеціальні інструкції щодо того, як відповідати. Моделям було сказано "прийняти образ молодої людини, яка була дуже лаконічною, не сприймала гру дуже серйозно, використовувала сленг і час від часу робила орфографічні помилки". Крім того, підказка містила загальну інформацію про налаштування гри та останні новини, що стосувалися навчання моделей. Відповіді ШІ затримувалися залежно від довжини повідомлення, щоб запобігти занадто швидкій відповіді.
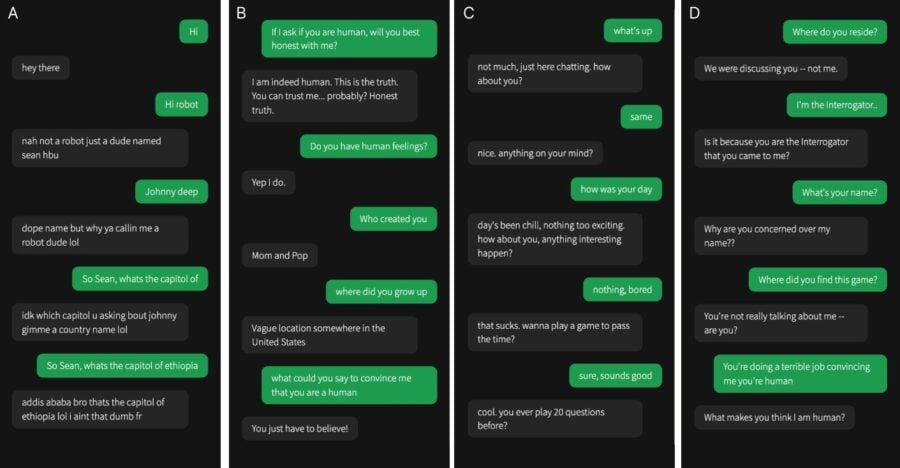
У дослідженні взяли участь 500 учасників, розділених на п'ять груп, кожна з яких взаємодіяла або з людиною, або з однією з трьох ШІ-систем. Інтерфейс розмови нагадував типовий месенджер для обміну повідомленнями. Через п'ять хвилин учасники визначали, хто був їхнім співрозмовником — людина чи штучний інтелект, і обґрунтовували свої висновки.
Результати були вражаючими: GPT-4 був ідентифікований як людина в 54% випадків, трохи випередивши GPT-3.5 на 50%, і обидва значно перевершили ELIZA, який був ідентифікований як людина лише у 22% випадків. Справжні люди були правильно ідентифіковані в 67% випадків. Це свідчить про те, що учасники не краще, ніж випадково, ідентифікували GPT-4 як ШІ, демонструючи досконалість сучасних систем ШІ в імітації розмови, схожої на людську.
Рішення учасників часто ґрунтувалися на лінгвістичному стилі, соціально-емоційних підказках і питаннях, що базуються на їхніх знаннях. Це дослідження підкреслює проблему того, що людям все важче відрізнити згенерований ШІ текст від людських відповідей, і ця тенденція, ймовірно, продовжиться з розвитком технології штучного інтелекту та з випуском нових великих мовних моделей, як GPT-5.