
Дослідники Microsoft анонсували нову модель штучного інтелекту для перетворення тексту в мовлення під назвою VALL-E, яка може точно імітувати голос людини, якщо отримати 3-секундний аудіозразок. Розпізнавши певний голос, VALL-E може синтезувати голос цієї особи, і робити це таким чином, щоб зберегти емоційний тон мовця, повідомляє ArsTechnica.
Творці VALL-E припускають, що його можна використовувати для високоякісних програм перетворення тексту в мовлення і створення аудіоконтенту в поєднанні з іншими генеративними моделями AI, такими як GPT-3.
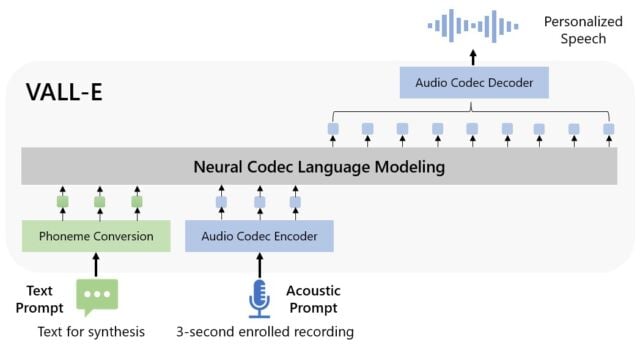
Microsoft називає VALL-E «моделлю мови нейронних кодеків», вона побудована на основі технології EnCodec, яку Meta представила в жовтні 2022 року. На відміну від інших методів перетворення тексту в мовлення, які зазвичай синтезують його шляхом маніпулювання сигналами, VALL-E генерує окремі коди аудіокодеків із текстових і акустичних підказок. По суті, він аналізує, як звучить людина, розбиває цю інформацію на окремі компоненти (так звані «токени») завдяки EnCodec і використовує навчальні дані, щоб узгодити те, що ШІ «знає» про те, як цей голос звучатиме, якби він вимовляв інші фрази.
На вебсайті VALL-E Microsoft надає десятки аудіоприкладів моделі ШІ в дії. Серед зразків «Speaker Prompt» — трисекундне аудіо, надане VALL-E, яке він має зімітувати. «Ground Truth» — це вже існуючий запис того самого мовця, який вимовляє певну фразу для порівняння (на зразок «контролю» в експерименті). «Baseline» є прикладом синтезу, який забезпечується звичайним методом синтезу тексту в мову, а зразок «VALL-E» є результатом моделі VALL-E.
Окрім збереження вокального тембру та емоційного тону оратора, VALL-E також може імітувати «акустичне середовище» зразка аудіо. Наприклад, якщо семпл надійшов із телефонного дзвінка, то він імітуватиме акустичні та частотні властивості телефонного дзвінка. А зразки Microsoft (у розділі «Синтез різноманітності») демонструють, що VALL-E може генерувати варіації голосового тону шляхом зміни випадкового початкового числа, яке використовується в процесі генерації.
Дослідники, схоже, усвідомлюють потенційну соціальну шкоду, яку може завдати ця технологія, тому зазначають наступне:
«Оскільки VALL-E може синтезувати мову, яка зберігає ідентичність мовця, це може нести потенційні ризики у неправильному використанні моделі, наприклад, підробити голосову ідентифікацію або видати себе за конкретного мовця. Щоб зменшити такі ризики, можна побудувати модель виявлення того, чи був аудіокліп синтезований VALL-E. Ми також застосуємо принципи Microsoft AI на практиці під час подальшої розробки моделей».