

У римському світі було багато письменності, яку можна було побачити як на імперських пам'ятниках, так і на предметах повсякденного вжитку, однак до наших часів збереглися лише фрагменти текстів, які були пошкоджені чи навмисно зіпсовані. Щоб допомогти історикам відновити ці написи, команда Google DeepMind представляє Aeneas — модель штучного інтелекту для відновлення стародавніх текстів з відкритим кодом.
Відновлення, датування та розміщення стародавніх написів практично неможливе без контекстуальної інформації. Традиційно у цих питаннях історики покладаються на власний досвід та спеціалізовані ресурси для виявлення "паралелей" — текстів, що мають спільні риси у формулюваннях, синтаксисі, стандартизованих формулах чи походженні. Aeneas була розроблена, аби пришвидшити цю роботу завдяки аналізу тисяч латинських написів та пошуку текстових й контекстуальних паралелей за лічені секунди.

Aeneas також може адаптуватися до інших стародавніх мов, писемностей та медіа, від папірусів до монет. Розробка великої мовної моделі проходила спільно з Ноттінгемським університетом та у партнерстві з дослідниками з університетів Ворвіка, Оксфорда та Афінського університету економіки та бізнесу. Заразом Google хоче, аби це дослідження приносило користь якомога більшій кількості людей, тому модель є повністю відкритою для дослідників, студентів, викладачів, музейних працівників та інших на сайті predictingthepast.com.
Розширені можливості моделі включають пошук паралелей у колекції латинських написів, обробку мультимодальних вхідних даних, як-от географічне походження тексту, та відновлення прогалини у текстах. Заразом Google DeepMind каже, що Aeneas має провідну продуктивність та "встановлює новий стандарт у відновленні пошкоджених текстів та прогнозуванні часу і місця їх написання".
Для навчання Aeneas Google створила великий набір даних на базі десятиліть роботи істориків. Всі записи очистили, гармонізували та пов'язали в єдиний "Латинський епіграфічний набір даних" (LED), де зібрали понад 176 тисяч латинських написів. Для роботи модель використовує декодер на основі трансформатора для обробки текстового введення напису, вслід за чим спеціалізовані мережі обробляють відновлення символів та датування за допомогою тексту, а географічна атрибуція використовує зображення написів як вихідні дані.
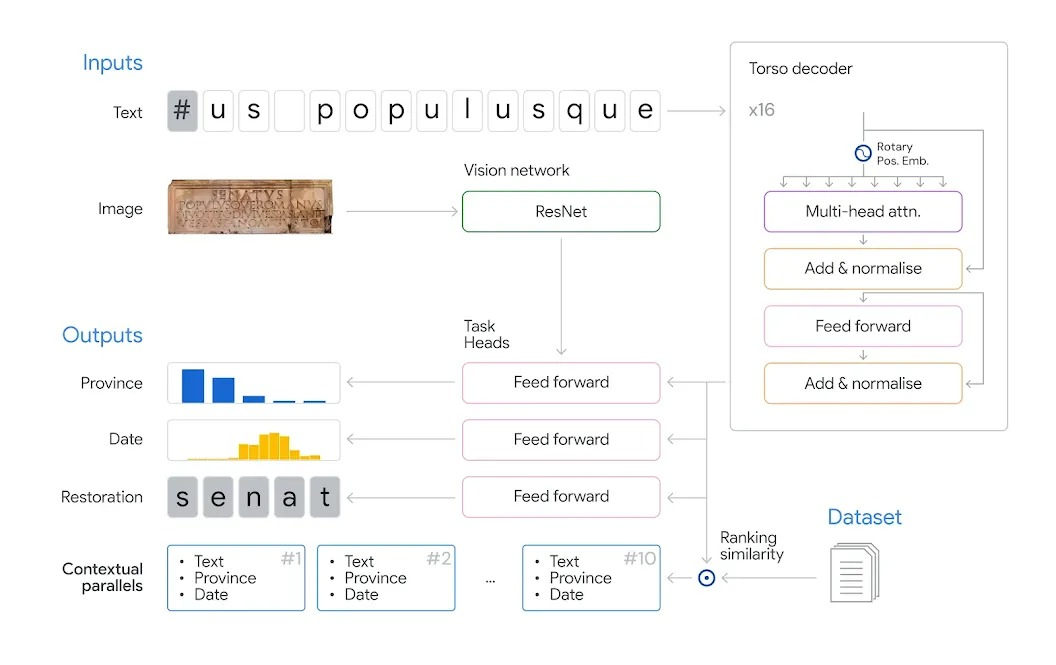
Кожен напис в Aeneas супроводжується списком схожих прикладів, який формується за допомогою методу “вбудовування” — способу кодування змісту та контексту напису у своєрідний історичний профіль. Такий підхід враховує тему тексту, мову, час і місце його створення, а також зв’язки з іншими написами.